A proposal to fix broken links on Stack Overflow
Posted on Fri 07 August 2015 in Side Activities
This post was published by me on Meta Stack Overflow on August 7th, 2015. I've republished it here so that I can easily update information related to recent developments. If you have questions or comments, I highly encourage you to visit the question on Meta Stack Overflow and post there.
This is a follow up to yesterday's post about how many links on Stack Overflow are starting to rot.
The proposal¶
I propose another hybrid of the previous broken link queue (as was mentioned above in comments and other answers) and an automated process to fix broken links with an archived version (which has also been suggested).
The broken link queue should focus on editing and fixing the links in a post (as opposed to closing it). It'd be similar to the suggested edits queue, but with the focus intended to correct links not spelling and grammar. This could be done by only allowing a user to edit the links.
One possibility, I envision is presenting the user with the links in the post and a status on whether or not the link is available. If it's not available, give the user a way to change that specific link. Utilizing this post, I have a quick mock up of what I propose such a review task looks like:
The Queue¶
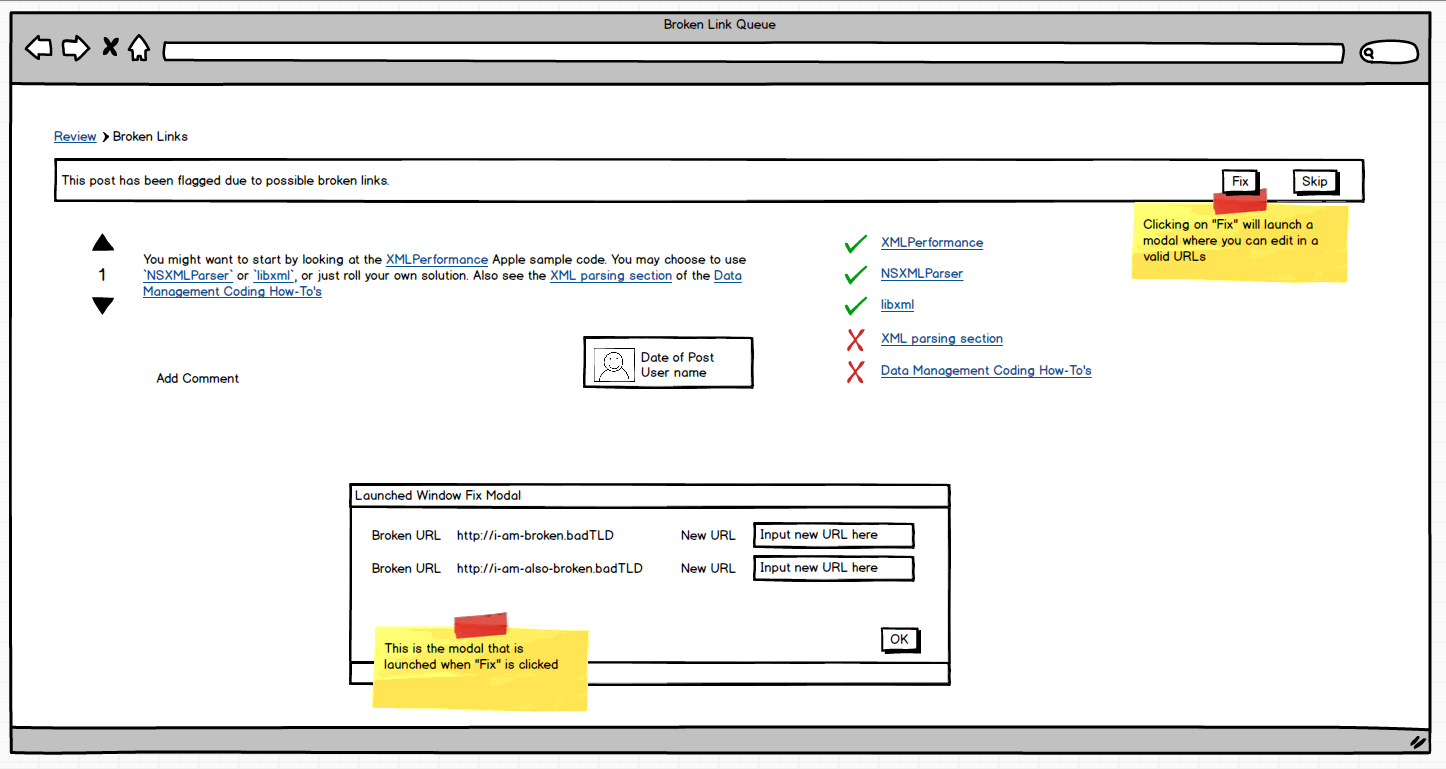
All the links that appear in the post are on the right hand side of the screen. The links that are accessible have a green check mark. The ones that are broken (and the reason for being in this queue) have a red X. When a user elects to fix a post, they are presented with a modal showing only the broken URLs.
The Automation¶
With this queue, though, I think an automated process would be helpful as well. The idea is that this would operate similarly to the Low Quality queue, where the system can automatically add a post to the queue if certain criteria are met or a user can flag a post as having broken links. I've based my idea on what Tim Post outlined in the comments to a previous post.
- Automated process performs a "Today in History" type check. This keeps the fixes limited to a small subset of posts per day. It also focuses on older posts, which were more likely to have a broken link than something posted recently. Example: On July 31, 2015, the only posts being checked for bad links would be anything posted on July 31 in any year 2008 through current year - 1.
- Utilizing the Wayback Machine API, or similar service, the system attempts to change broken links into an archived version of the URL. This archived version should probably be from "close" to the time the post was originally made. If the automated process isn't able to find an archived version of the link, the post should be tossed into the Broken Link queue
- When the Community edits a post to fix a link, a new Post History event is utilized to show that a link was changed. This would allow anyone looking at revision history to easily see that a specific change was only to fix links.
- Actions performed in the previous bullets are exposed to 10K users in the moderator tools. Much like recent close/delete posts show up, these do as well. This allows higher rep users to spot check (if they so desire). I think this portion is important when the automated process fixes a link. For community edits in the queue, the history tab in
/reviewseems sufficient. - If a post consists of a large percentage of a link (or links) and these links were changed by Community, the post should have further action taken on it in some queue.
Example: - A post where X+% of the text is hyperlinks is very dependent on the links being active. If one or more of the links are broken, the post may no longer be relevant (or may be a link only post). One example I found while doing this was this answer.
I don't think that this type of edit from the Community user should bump a post to the front page. Edits done in the broken link queue, though, should bump the post just like a suggested edit does today. By preventing the automated Community posts from being bumped, we prevent the the front page from being flooded, daily, with old posts and these edits. I think that the exposure in the 10K tools and the broken link queue will provide the visibility needed to check the process is working correctly.
Process flows¶
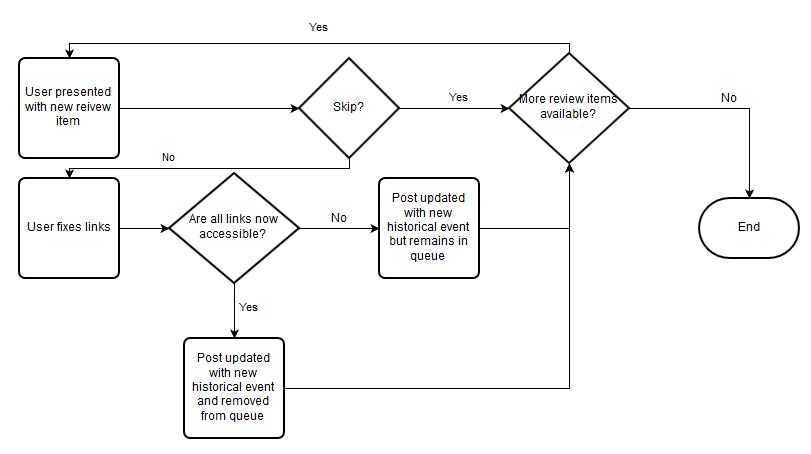
Queue Flow:
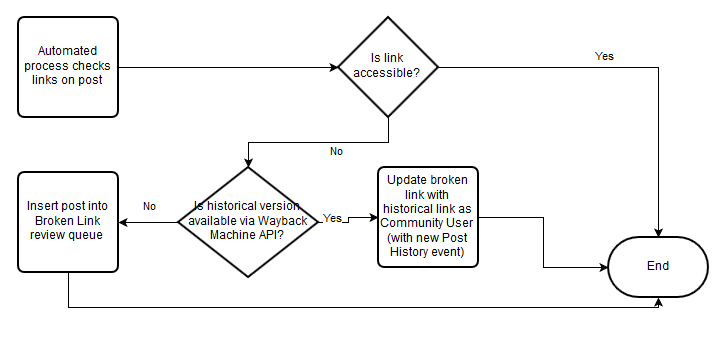
Automated process flow:
Potential pitfalls¶
The automated link checking will likely run into several of the problems I did. Mainly:
- Sites modify the
HEADrequest to send a 404 instead of a 405. My solution to this was to issueGETrequests for everything. - Sites don't like certain user agents. My solution to this was to mimic the Firefox user agent. To be a good internet citizen, Stack Exchange probably shouldn't go that far, but providing a unique user agent that is easily identifiable as "StackExchangeBot" (think "GoogleBot"), should be helpful in identifying where traffic is coming from.
- Sites that are down one week and up another. I solved this by spreading my tests over a period of 3 weeks. With the queue and automatic linking to an archived version of the site, this may not be necessary. However, immediately converting a link to an archived copy should be discussed by the community. Do we convert the broken link immediately? Or do we try again in X days. If it's still down then convert it? It was suggested in another answer that we first offer the poster the chance to make changes before an automatic process takes place.
- The need to throttle requests so that you don't flood a site with requests. I solved this by only querying unique URLs. This still issues a lot of requests to certain, popular, domains. This could be solved by staggering the checks over a period of minutes/hours versus spewing 100s - 1000s of
GETrequests at midnight daily.
With the broken link queue, I feel the first two would be acceptable. Much like posts in the Low Quality queue appear because of a heuristic, despite not being low quality, links will be the same way. The system will flag them as broken and the queue will determine if that is true (if an archived version of the site can't be found by the automated process). The bullet about throttling requests is an implementation detail that I'm sure the developers would be able to figure out.